Les 7 avancées clés de Deepseek dans le domaine des LLMs.
Ça semble pas intéresser grand monde, mais vous voulez vraiment savoir ce qui rend DeepSeek unique ? Et surtout comment ils ont pu faire un modèle 20 fois moins cher qu’OpenAI ? Allez, on détaille :
1. Le grand retour du RL direct
DeepSeek a remis le Reinforcement Learning (RL) au centre du jeu, mais avec une approche nouvelle. Plutôt que de dépendre d’un entraînement supervisé coûteux en amont, ils appliquent directement du RL sur le modèle de base, sans passer par la case "fine-tuning classique".
👉 Résultat : moins de ressources utilisées, un entraînement plus rapide et pas besoin de tout recommencer à zéro à chaque amélioration. C’est plus simple, mais surtout bien plus efficace.
2. RL + Chain-of-Thought (CoT) : combo gagnant
Là où DeepSeek va plus loin, c’est en couplant le RL avec des chaînes de raisonnement, ou Chain-of-Thought (CoT).
👉 Ça permet au modèle de dérouler un raisonnement logique pas à pas, ce qui est crucial pour des tâches complexes comme les maths, le codage ou les problèmes scientifiques.
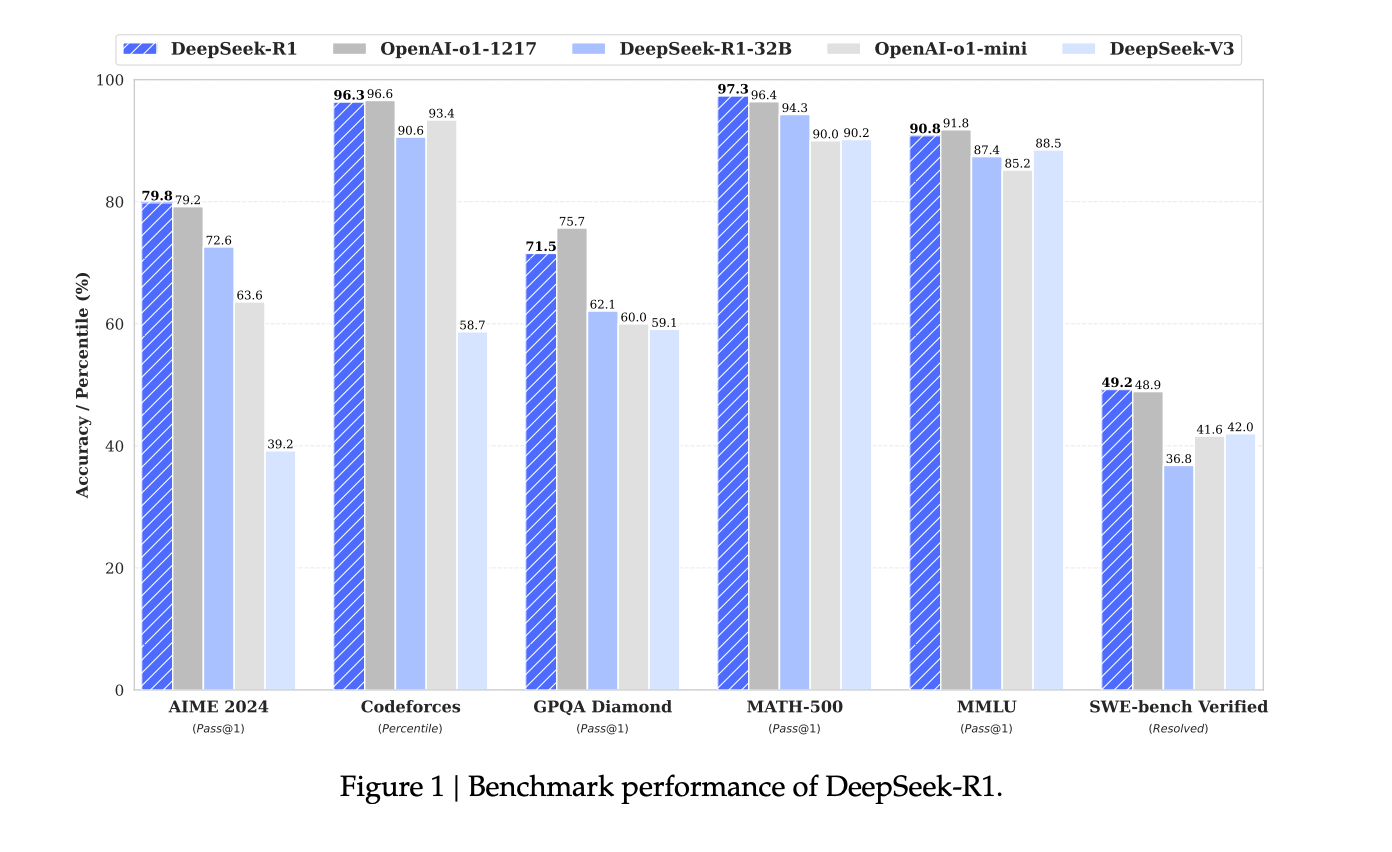
👉 Exemple concret : sur le benchmark MATH-500, DeepSeek-R1 a atteint un score impressionnant de 97,3 %, dépassant la plupart des autres modèles.
3. Distillation : petits modèles, grandes perfs
Ils ont aussi réussi à "distiller" les capacités des grands modèles vers des versions plus petites. Autrement dit, ils prennent tout ce qui est puissant dans le modèle principal et le condensent dans des modèles plus légers.
👉 Résultat : les versions distillées (comme DeepSeek-R1-Distill-Qwen-7B) performent mieux que certains modèles plus gros, tout en consommant moins de ressources.
👉 Pour les applications avec des contraintes de coût ou de calcul, c’est un énorme avantage.
4. Des réponses claires et humaines
Une des grandes forces de DeepSeek, c’est l’attention portée à la lisibilité des réponses. Grâce à une phase de "Cold Start", ils ont fine-tuné le modèle avec des données ultra-précises, rendant les réponses :
- Claires et bien structurées,
- Sans mélange de langues ni contenu confus.
👉 Le tout est renforcé par des "récompenses" lors du RL, pour aligner le modèle avec ce que les humains préfèrent lire.
5. Raisonnement auto-évolutif et "aha moments"
Pendant l’entraînement, des comportements fascinants ont émergé :
👉 Le modèle apprend à prolonger ses réflexions, à corriger ses propres erreurs et à explorer des stratégies alternatives pour résoudre un problème.
👉 Ce qu’ils appellent les "aha moments" montrent que le RL peut pousser un modèle à évoluer de façon autonome, sans intervention humaine directe.
6. Des performances comparables à OpenAI
DeepSeek-R1, malgré un coût bien inférieur, rivalise avec les modèles phares d’OpenAI (comme le o1-1217) sur plusieurs fronts :
- Mathématiques et raisonnement scientifique : scores similaires ou supérieurs.
- Codage : expert sur des compétitions comme Codeforces.
- Écriture et tâches créatives : des scores impressionnants sur des benchmarks comme AlpacaEval et ArenaHard.
7. Un pipeline novateur en plusieurs étapes
Pour arriver à ces résultats, DeepSeek utilise un pipeline d’entraînement bien pensé :
Cold Start : fine-tuning initial avec des données propres et structurées.
RL ciblé : amélioration des capacités de raisonnement logique.
Rejection Sampling : collecte de nouvelles données en rejetant les mauvaises réponses.
RL global : alignement avec les préférences humaines sur une grande variété de scénarios.
👉 Cette méthode permet d’affiner les performances à chaque étape, tout en restant efficace et économe.
Conclusion : DeepSeek, c’est moins cher, plus rapide et incroyablement efficace. En remettant le RL au centre, en distillant les capacités des grands modèles et en optimisant chaque étape, ils redéfinissent ce qu’on peut attendre des modèles de langage. Vous la sentez, la révolution ? 😊